The Remarkable Effects Produced by Requesting a High Code Coverage for Testing
How we solved the never-ending debate on pains and gains of code coverage constraints

Improving the Code Quality
Back in 2019, as an architect, I was involved in discussions at our company’s architecture committee to consider making the code coverage a requirement to reach the quality gate we used in our build chain.
It may sound obvious today, but at that time, it wasn’t, mainly because a single configuration was used for the whole IT, regardless of the age of apps to maintain or how teams used to work.
On the one hand, multiple teams shared one or two massive applications, making the releasing and testing processes pretty complex. They typically had to agree on release planning, with weeks booked for (manual) testing.
On the other hand, there were finer-grained applications (actually, Java / Spring Boot microservices), which were more suitable for Continuous Delivery, with their lifecycle and single ownership, and many automated tests. But again, depending on the teams’ habits, the usage of automated tests varied a lot.
Defining an Action Plan
After a bit of research, we came up with a few proposals for the committee, and we refined them to the three following options:
- Keep it as of today, i.e., no coverage is needed for the quality gate.
- Set a low rate (e.g., 50%) required for coverage of the new code, then increase it every x months until the final objective is reached.
- Immediately set a high rate (e.g., 80%) on new code.
Note: the new code is defined as any added or modified code. This means that we first have to take the current state of the code to determine a baseline, and only the delta is taken into account to meet the rate requirement.
The first option was a regression in the code quality perspective, as no improvement was brought, plus it would let technical debt accumulate. This was clearly in contradiction with the mission of our architecture committee.
The second one looked promising, as it was a concession with a facilitated adoption by dev teams and an eventual improvement in a long-term vision. But it would also bring additional concerns, as it would need regular rate upgrades, with just as frequent developers’ complaints.
We finally chose the third option, mainly for its faster improvement curve.
And also because we were deeply convinced that most of our colleagues were skilled enough to reach this target.
Softening the Strictness of Our Decision
But we weren’t architects out of touch with reality (ivory tower syndrome) since we were all part of development and operation teams.
This is why we qualified the plan above with two significant restraints:
- Not every app suits this new rule because of its age and technology. The decision would thus only apply to apps belonging to the microservice world, which are already running in a CD pipeline. Legacy apps could still live their life until they are replaced.
- Not every single line of code was to be covered: boilerplate code like getters and setters don’t bring logic that requires testing. Controllers, Spring Contexts, and DAO classes were also excluded, as we considered we shouldn’t test frameworks we rely on — but this is only valid when these classes don’t contain business logic.
Note: the exceptions listed above were not required to be tested, but it was allowed to do it. Moreover, they often were tested with contract-, integration-, and component-tests. Still, since it wasn’t unit testing per se, the code coverage report agent did not consider them.
The focus was put on code where the actual logic stands: services, helpers, validators, converters, etc., which represented the vast majority of our codebase.
Debating the Percent
We had the strategy, but we still had to agree on the numbers: the minimal code coverage rate. Is 50% enough? What about 70% or 90%?
One of us had proposed to require 60% for coverage. As a justification, she said it sounded reasonably acceptable to her team.
I was personally advocating for a much higher requirement. I argued that we reasonably could not deliver software where 40% of the business logic is not tested. Even 20% untested was a lot to me.
Would you buy a product where almost half of the logic is untested?
We also agreed that 100% was nonsense, as it wouldn’t allow a single exception. Undoubtedly, it would lead to a fierce disagreement among developers and the potential abandonment of this unpopular measure.
90% was a bit high as a first step. Some pieces of code can hardly be tested due to technical and language constraints. As an illustration in Java, consider an enum class used in a switch statement. Best practices (which are often implemented in static code analysis tools) recommend having a default branch to guarantee that all cases are handled. But in fact, this fallback is unreachable if a case is already defined for each possible value:
private enum Result {
NEW, RUNNING, SUCCESSFUL, FAILED;
}
boolean isOver(Result result) {
return switch (result) {
case SUCCESSFUL, FAILED -> true;
case NEW, RUNNING -> false;
default -> throw new RuntimeException("Unexpected result"); // Unreachable
};
}Finally, we just went with the recommended settings of the tool, 80%.
In my team, this number was also totally justified because the current overall coverage of our code was about 70% on average — and 77% with weighted arithmetic mean (where weights are the number of lines).
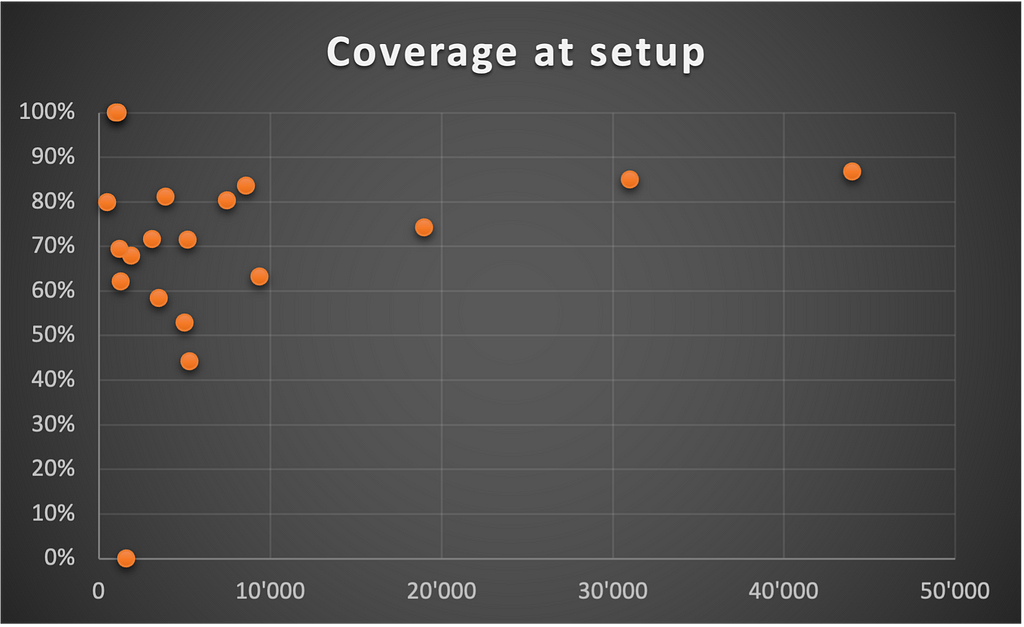
Opening Pandora’s Box
As expected, we got negative feedback as soon as the setup was live, even though it was initially fine with everybody on principle.
At first glance, the new rule sounded like a counter-productive initiative.
Some fixes couldn’t be delivered as quickly as before. In some cases, a small piece of code had to be changed, but since the class was not tested at all, developers were forced to add the missing tests, resulting in a notable delay. In the same idea, it was also reported that some crucial tasks were not completed on time in the sprints due to the code quality requirements.
Time-to-market capability is seriously impacted, they said.
We heard all this and discussed it but stood in our position because we were convinced it was worth spending the effort. However, we decided that each team had to take responsibility for the products they manage:
If you don’t stick to the architects’ recommendation, fine, but you must assume it in front of managers, customers, and auditors.
Reaping the Rewards
That wasn’t a pleasant time. But guess what happened four months later?
The overall coverage of our products had remarkably increased.
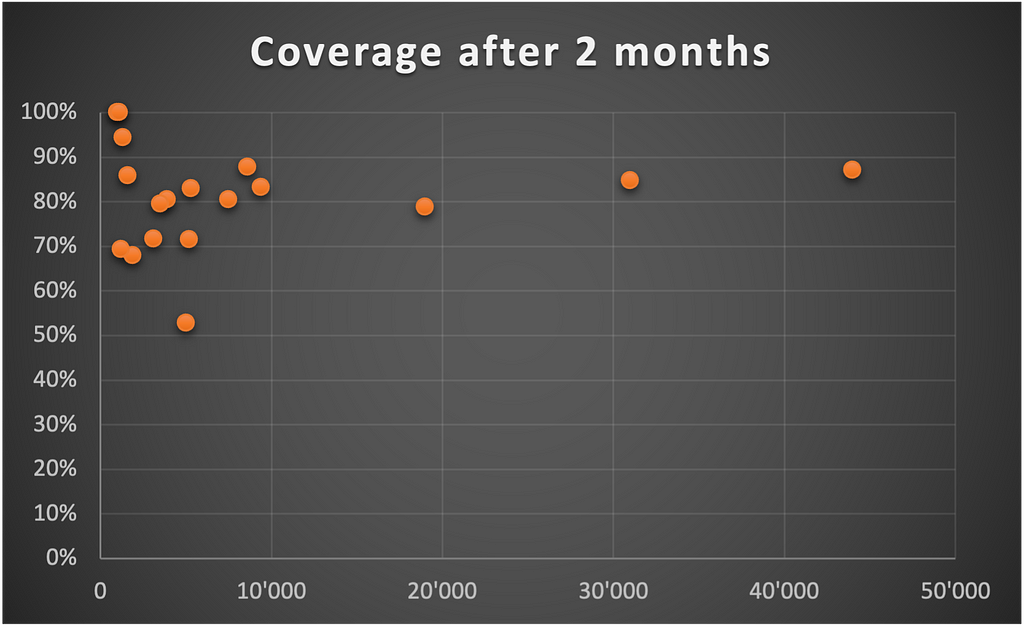
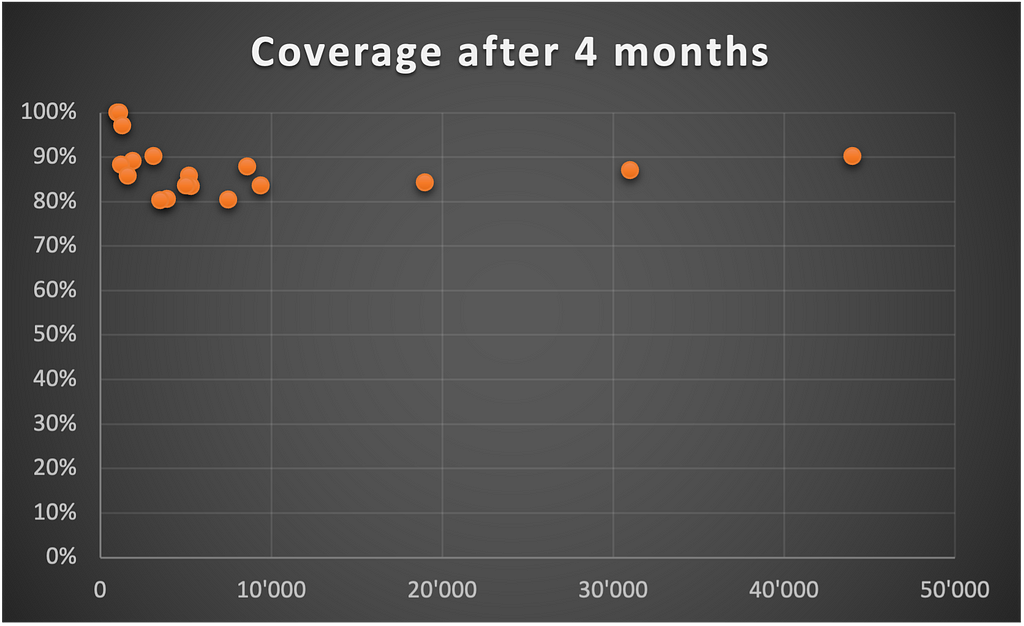
Why?
After the first criticism came the first actions. Developers don’t like when work cannot be completed within the sprint. So they started to propose tasks to improve the coverage when the workload was a bit lower.
It took only four months to move from a situation where some products had no tests to an acceptable minimum of 80% of overall code coverage.
Under the hood, there were some additional benefits we didn’t expect: documentation and learning. Writing tests on existing code requires understanding the code first. Tests can then serve as documentation because they tell us what the behavior of a method is and what errors must be managed.
Final Considerations
All this happened a few years ago, and one may wonder why I post this article now. The reason is the effect is still visible, although we never revised the 80% rate.
As of today, we could even request 90% instead because all microservices maintained by my team has an overall coverage higher than 93%.
I genuinely believe it was an excellent decision, and most of my colleagues proved to accommodate well with such a high code quality standard.
It reflects what my team is: skilled and passionate.
Resources
The Remarkable Effects Produced by Requesting a High Code Coverage for Testing was originally published in Better Programming on Medium, where people are continuing the conversation by highlighting and responding to this story.