When Production Doesn’t Care About Holidays
An unexpected surge of orders revealed a hidden system limit and taught me lasting lessons about teamwork, pressure, and testing.

It was the last working day before Christmas, and everything was supposed to slow down.
Instead, one of our warehouses suddenly stopped processing orders entirely.
Within minutes, hundreds of employees were waiting for our system to come back to life.
It Started Like Any Other Day
Friday, December 23rd, 2016. Christmas was about to happen — the last working day for many people before the holidays. I was working as a senior software engineer in the Logistics department of our e-commerce (or more precisely e-grocery) company. As for many retailers, the days preceding Christmas are the most crucial, with the highest demand, and both IT systems and warehouse workers are heavily solicited.
While we were peacefully working (and enjoying pre-winter coffee breaks), the on-call mobile phone rang: a whole warehouse was completely stuck. No orders were being loaded into the system, which meant nothing could be prepared. At that time, the company only had two warehouses, meaning that half of the production had stopped. Not being able to deliver orders to customers would have been a disaster, both for our public image and, of course, financially.

The warehouse manager told us that all employees were literally unable to work anymore. They were forced to stop and wait for us to fix the issue. But time was running out, as we had very strict deadlines to meet so orders could still be shipped and delivered on time.
Something Was Wrong
My team rushed to their keyboards and mice, trying to understand what was happening. Fortunately, our logging systems were quite efficient, and since I was mainly working on the order planning system, I quickly located the issue. There was a SQL error when trying to load the orders to pick. What the heck — how could this suddenly happen?
Trying to Understand What Happened
The error message was actually quite clear. The SQL query contained a WHERE ... IN (...) clause enumerating each order ID, and we had reached the limit imposed by the JDBC SQL Server driver (2100 items). Soon we realized this was caused by the exceptional load that day: we were probably beating our historical record for daily orders (apparently more than 2100).
Too many parameters were provided in this RPC request. The maximum is 2100.
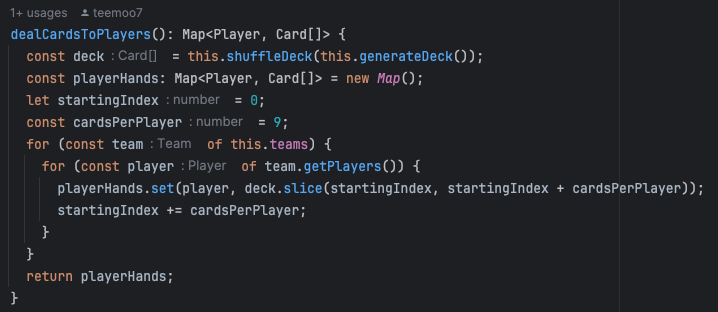
I immediately started thinking about a fix: splitting orders into chunks of 2000 items and reconciling the results afterward. While it didn’t seem very complex, the situation was stressful — not ideal for experimentation. Luckily, I remembered seeing similar code a few days earlier, so I could derive an implementation for my use case fairly quickly.
At some point, while I was trying hard to focus on my code, I heard an intense discussion nearby. The Chief Logistics Officer had entered the room to get updates and ask about resolution time.
While his presence was understandable, my Engineering Manager intercepted him before I was disturbed. Later, I learned that my manager had acted as a firewall, protecting my focus. He answered questions and absorbed most of the pressure himself.
I already knew that hundreds of employees were stuck. I could feel the stress and tension. But having a C-level executive looking over my shoulder would definitely not have helped.
A Question That Changed Everything
After a few minutes, I had code ready. I was confident it would work, as it was inspired by an existing implementation — something I considered proven. At least, I wouldn’t make things worse.
Then our Architect — a very smart and kind person — asked whether I had tested the code. Although I strongly believed in testing, I felt embarrassed. There was a lot of pressure to deliver quickly. Testing seemed difficult because we would need thousands of orders in the test system, and generating that much data felt too time-consuming.
Precisely because the situation is urgent and stressful, testing is even more crucial.
The Architect told me something I will never forget: precisely because the situation was urgent and stressful, testing was even more crucial. We didn’t want to ship a fix that failed — or worse, made things worse.
I eventually realized I didn’t need performance or load testing. I only needed to validate the SQL grammar. I wrote a simple integration test generating 2500 IDs (just incrementing a counter), calling the DAO with this array, and verifying that no error was thrown. The partitioning logic could also be unit-tested independently.
Fixing It
Finally, I shipped the fix and had it deployed within minutes. Although the pressure was still there, I must admit I felt much more confident knowing the code was tested.
And the magic worked. Orders started loading again, and warehouse employees could resume work. We had lost some time, and they now had to rush to prepare everything, but at least operations were no longer blocked. Delivery partners had been informed about the delay and adapted the rest of the process.
I felt completely exhausted, with mixed emotions. I felt sorry that warehouse colleagues had to rush because of a bug in our systems. But I was also relieved when deadlines were met, customers were not impacted, and the company avoided major losses. And yes — I was proud of myself.
What This Taught Me
I learned several lessons from this incident:
- Even if code works fine 99% of the time, it may still fail because of a corner case, an exceptional load, or specific conditions on a particular day. Never be overconfident.
- In the repository, I can still see my commit, and I am proud to be its author. But I never forget it was teamwork. My manager brilliantly acted as a firewall, handling strategic and business pressure so I could focus on the technical solution.
- And I remain grateful to our Architect for teaching me that urgency is exactly when automated tests matter the most.
Takeaways
- SQL queries using WHERE ... IN (...) clauses have hard limits and scale poorly with large numbers of items.
- Always ship tests with your hotfixes.
- As a manager, trust your developers and avoid propagating stress to them.
- A system that works most of the time may still fail on special days or under exceptional load.
Behind every “successful delivery” notification, there are moments like this — invisible to customers, but unforgettable for the engineers and operators making it work.
When Production Doesn’t Care About Holidays was originally published on Medium, where people are continuing the conversation by highlighting and responding to this story.